La Inteligencia Artificial (IA) está transformando todos los sectores, y configurar un entorno adecuado para trabajar en IA es esencial para poder aprovechar al máximo las herramientas y servicios disponibles. Azure Databricks es una plataforma unificada de análisis de datos y ciencia de datos basada en Apache Spark, que permite a los equipos desarrollar, entrenar y desplegar modelos de IA de manera eficiente. En esta guía paso a paso, aprenderás cómo configurar tu propio entorno de IA en Azure Databricks.

1. ¿Qué es Azure Databricks y por qué usarlo para IA?
Azure Databricks es un servicio de análisis colaborativo que se basa en Apache Spark, diseñado para simplificar el proceso de creación, entrenamiento e implementación de modelos de machine learning (ML) e inteligencia artificial (IA). Algunas de las ventajas clave de usar Azure Databricks incluyen:
- Escalabilidad: Puedes trabajar con grandes volúmenes de datos sin preocuparte por el rendimiento.
- Integración: Se integra perfectamente con otros servicios de Azure, como Azure Machine Learning, Azure Blob Storage, y Azure Data Lake.
- Colaboración: Los Notebooks de Databricks permiten la colaboración en tiempo real entre científicos de datos, ingenieros y otros miembros del equipo.
2. Requisitos Previos
Antes de comenzar, asegúrate de tener lo siguiente:
- Una cuenta de Azure: Si aún no tienes una cuenta, regístrate en Azure.
- Permisos de administrador: Necesitarás permisos para crear recursos dentro de Azure, como clúster y servicios de almacenamiento.
- Conocimientos básicos de Python y Machine Learning: Aunque no es estrictamente necesario, tener algo de experiencia con Python y ML puede facilitar el proceso.
3. Paso 1: Crear una Cuenta de Azure y Acceder a Azure Databricks
-
Inicia sesión en tu cuenta de Azure: Dirígete a portal.azure.com y accede con tus credenciales de Microsoft.
-
Crea una nueva instancia de Azure Databricks:
- En el portal de Azure, selecciona “Crear un recurso”.
- Busca “Azure Databricks” y haz clic en “Crear”.
- Completa los detalles del recurso, como nombre, suscripción, grupo de recursos, y región. Después, haz clic en “Revisar y crear” y luego en “Crear”.
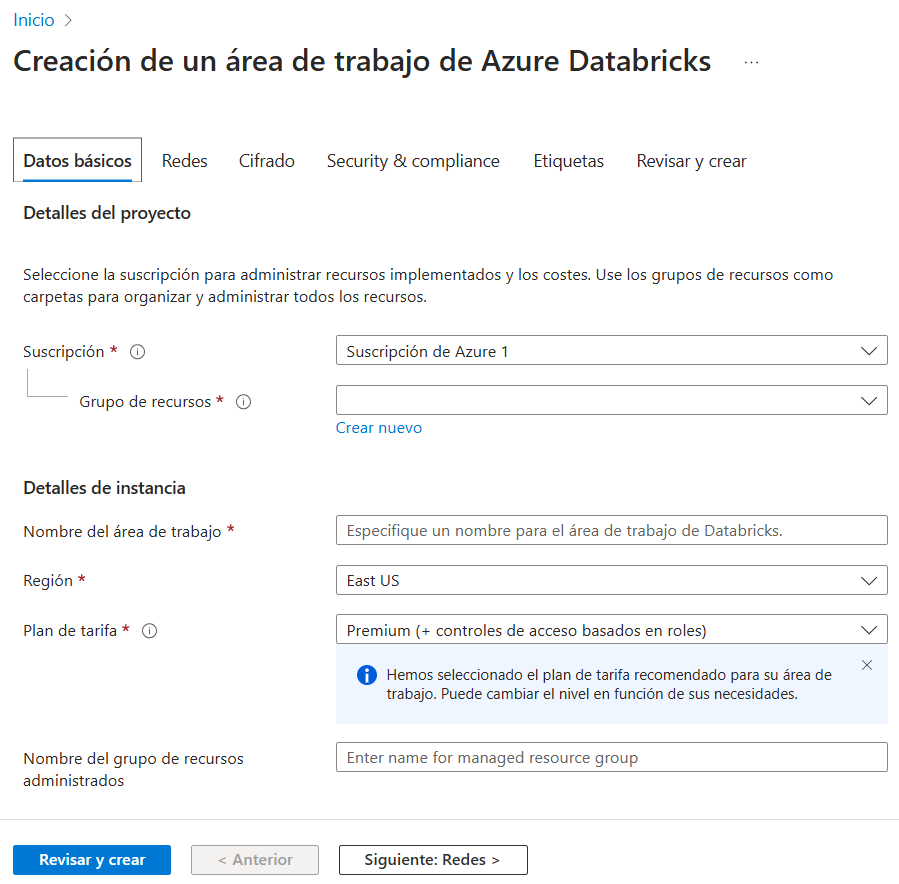
-
Accede a Azure Databricks:
- Una vez creado el recurso, selecciona “Ir al recurso” para abrir el entorno de Azure Databricks.
- Inicia sesión en la plataforma usando tus credenciales de Azure.
4. Paso 2: Crear un Clúster en Azure Databricks
Los clústeres en Azure Databricks son entornos de ejecución donde se realizarán los procesos de análisis de datos y entrenamiento de modelos de IA. Para configurarlo:
-
Ir a la sección de Clústeres:
- En el dashboard de Azure Databricks, selecciona “Clusters” en la barra lateral.
-
Crear un nuevo clúster:
- Haz clic en “Crear clúster”.
- Ingresa un nombre para el clúster y selecciona el tipo de runtime adecuado. Para proyectos de IA, selecciona un runtime que tenga soporte para Python, TensorFlow, y PyTorch.
- Establece el número de nodos según el tamaño y la carga de trabajo de tu proyecto (puedes comenzar con una configuración pequeña y ajustarlo más tarde).
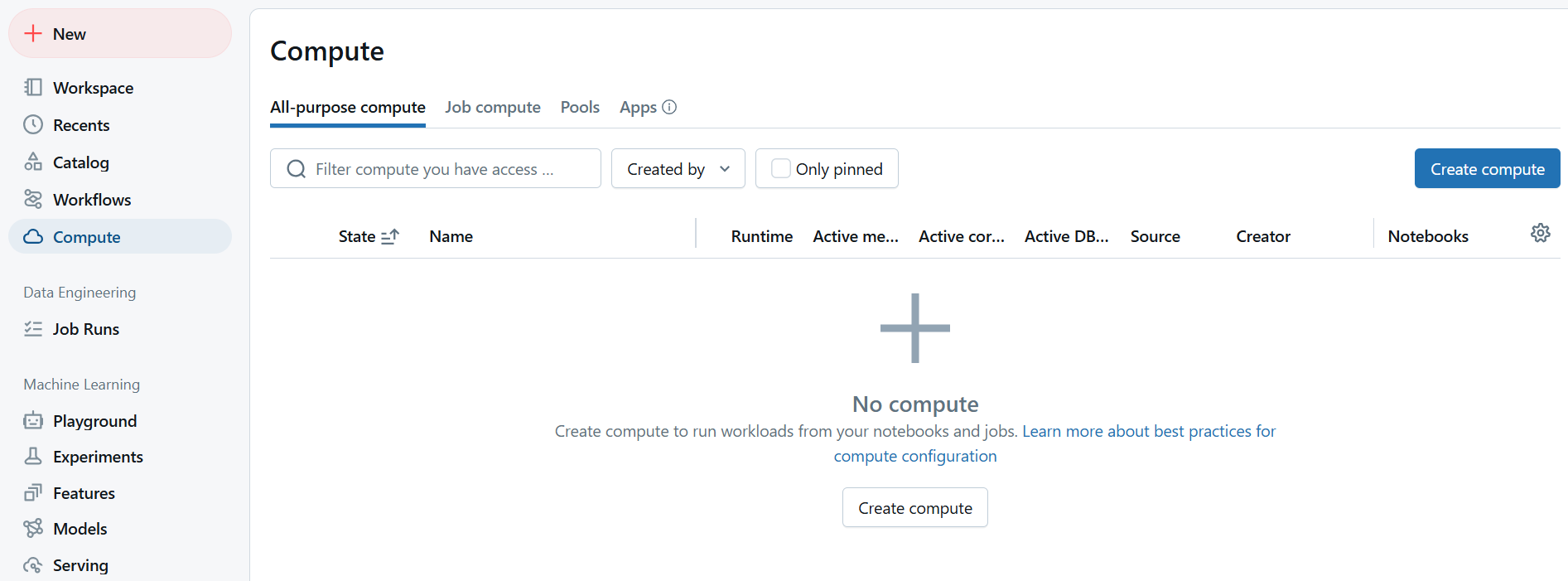
-
Configurar las opciones avanzadas (opcional):
- Puedes ajustar configuraciones avanzadas como el tamaño de los nodos, el tipo de almacenamiento, etc.
-
Iniciar el clúster:
- Haz clic en “Crear” y espera a que el clúster esté listo. Esto puede tardar algunos minutos.
5. Paso 3: Crear y Configurar un Notebook en Azure Databricks
Notebooks es donde escribirás y ejecutarás tu código para proyectos de IA. Azure Databricks proporciona un entorno basado en Jupyter Notebooks que permite la escritura de código en Python, R y SQL. Para crear un nuevo Notebook:
-
Acceder a la sección de Notebooks:
- En el panel de Azure Databricks, selecciona “Workspace” y luego “Create” > “Notebook”.
-
Elegir un lenguaje de programación:
- Selecciona el lenguaje que prefieras (Python es comúnmente usado para IA). Asocia el Notebook al clúster que creaste anteriormente.
-
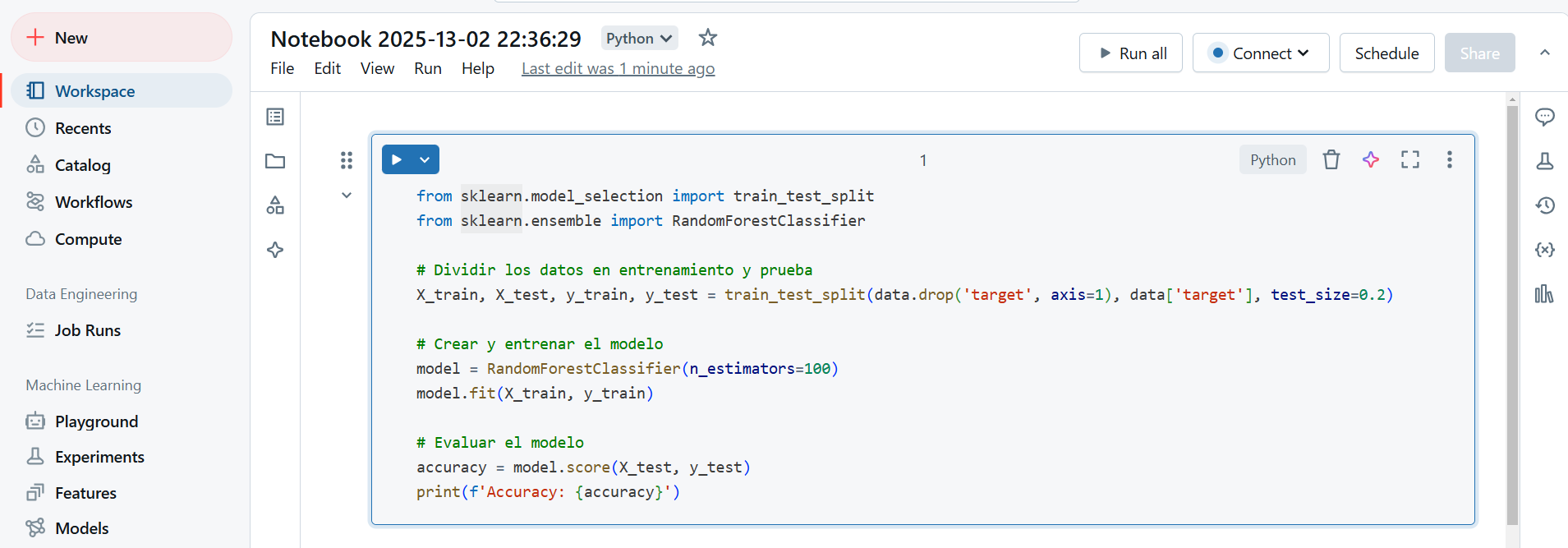
Escribir código para IA:
- Dentro del Notebook, escribe el código necesario para cargar datos, preprocesarlos y entrenar un modelo de IA. Por ejemplo, puedes cargar un dataset con Pandas, preprocesarlo y luego utilizar scikit-learn o TensorFlow para entrenar un modelo.
6. Paso 4: Conectar a Fuentes de Datos en Azure
Para que tu entorno de IA en Azure Databricks funcione correctamente, necesitarás acceder a tus datos. Azure Databricks se integra perfectamente con varias fuentes de datos en Azure:
- Acceder a Azure Blob Storage:
- Para cargar datos desde Azure Blob Storage, utiliza la conexión de DBFS (Databricks File System), lo que permite a los usuarios leer y escribir datos en el almacenamiento en la nube.
-
- Azure Databricks también puede conectarse a otras fuentes de datos como Azure Data Lake, SQL databases, y Data Warehouses.
7. Paso 5: Entrenamiento de Modelos de IA en Azure Databricks
Una vez que tu entorno esté listo, puedes empezar a entrenar tus modelos de IA. Azure Databricks soporta diversas bibliotecas de Machine Learning y Deep Learning como TensorFlow, PyTorch, y XGBoost.
Ejemplo de entrenamiento con scikit-learn:
8. Paso 6: Despliegue y Monitorización del Modelo
Una vez que tu modelo esté entrenado y evaluado, es hora de desplegarlo para hacer predicciones en tiempo real. Azure Databricks permite integrar modelos con Azure Machine Learning para realizar el despliegue.
- Despliegue del modelo:
- Utiliza la API REST de Azure Machine Learning para poner tu modelo en producción.
- Monitorización y mantenimiento:
- Azure proporciona herramientas como Azure Monitor para seguir el rendimiento del modelo y realizar ajustes según sea necesario.
9. Conclusión
Configurar un entorno de IA en Azure Databricks es un proceso directo y escalable, que te permite comenzar a trabajar rápidamente con grandes volúmenes de datos y modelos avanzados de Machine Learning. Con la potencia de Apache Spark, el soporte para bibliotecas populares y la integración con otras soluciones de Azure, Azure Databricks se convierte en una plataforma esencial para cualquier proyecto de IA.
Llamada a la acción
¡Es hora de comenzar! Si deseas dar tus primeros pasos en el mundo de la inteligencia artificial, Azure Databricks es el lugar ideal para crear, entrenar e implementar tus modelos de IA. Sigue esta guía paso a paso y empieza a aprovechar todo lo que esta poderosa plataforma tiene para ofrecer.
Si deseas profundizar en estos conocimientos y aplicarlo en tu negocio Contáctanos nuestro equipo de expertos te asesorará y llevará por este hermoso camino.
Explora Nuestros Servicios
